KRaft or Zookeeper
本篇将主要对比一下 Kafka 元数据管理方面的变化
Kafka 2.8 与之前版本相比,最重要的变化莫过于内部实现了 KRaft 用以替代 Zookeeper 进行元数据的管理。
详情见 KIP-500,此处做一些大致的总结
其他参考资料:
KRaft: Apache Kafka Without ZooKeeper
Kafka 在 2.8 的版本中新增了 KRaft 模式,正式宣布 Kafka 将逐步移除对 Zookeeper 的依赖。
Kafka 推出的 3.x 版本将弃用 Java8,将在 4.x 中正式移除
KRaft 模式目前不建议应用于生产环境 !
背后的推动力#
使用 Zookeeper 管理元数据会遇到的问题#
配置复杂
使用 Zookeeper 做一致性服务最显著的优势就是可靠,但是对于 Kafka 这种追求轻量级、开箱即用的组件,Zk 就会显得十分笨重。
Zk 有自己的配置文件、管理工具、部署文档,这就意味着管理员需要付出额外的成本去学习 Zk,这极大的提高了 Kafka 使用者的门槛。
性能瓶颈
2.7 及之前版本中,Kafka 将元数据存储在 Zookeeper 中从而实现一致性。
Zk 负责管理 Broker、Partition、Controller 的元数据,但 Zk 对高并发的写入并不友好。
面对大型集群,Topic 和 Partition 达到一定规模后,Zk 中的元数据可能会被频繁的修改,但 Zk 并不支持批量写入或是分组写入,只能对节点进行逐个的修改,从而也成了数据同步时的瓶颈。
Kafka 0.9 就曾因类似问题,将 Topic、Consumer 的元数据完全迁移至 Broker 中进行管理。
状态不一致
Broker 之间
使用 Zk 管理元数据的 Kafka 将各个 Broker 状态的变化视为独立的事件。
当 Controller 向所有 Broker 同步状态时,A(Broker)可能会因为某些原因没有同步成功, Controller 重试几次后最终就会放弃。
而这时,集群中 Broker 的状态就出现了不一致,并且 A 永远也不可能同步到其他 Broker 当前的状态(因为 Controller 已经放弃重试了)。
Broker 之间的不一致并不影响主要功能的正常使用,但从监控角度来说,A 相当于丢失了一次状态的信息。
Zk 与 Controller
这是一个较为严重的问题,Zk 中的元数据很有可能和 Controller 内存中的数据不一致。
比如当 分区 Leader 更改了分区元信息(存储在 Zk 中),Controller 可能数秒之后才能同步到该消息。原因是 Zk 并没有提供一个通用的监控接口。
Zk 目前提供的 Watch 只能监听节点的变化,而无法得知节点变化的内容。这就让 Controller 监听到变化后不得不再去访问一次 Zk 才能同步分区的元信息。而且 Watch 的数量是有限制的,过多也会影响性能。
监控数据获取繁琐
Zk 只负责管理 Kafka 某一时刻的状态,而没有管理状态的历史变更记录。
这就让我们搭建监控系统的时候变得无比繁琐,不仅很多数据要绕一圈从 Zk 获取,获取到的数据还要自己做一个时序的存储才能进行统计分析。
KRaft#
我们经常会谈论到使用事件流来管理集群状态的优势。比如 Kafka 对消费者位移的管理,任何一个消费者需要更新状态时,都只需要重放一遍(消费)比自己位移更大的事件就能到达最新的状态。
但是 Kafka 自身却没有应用这种优势。KRaft 模式可以算是实现这个理念的一次尝试。并且与其将这些元数据存储在 Zk 这个独立的系统中,不如由 Kafka 自身来管理这些元数据。
主要优势
可以完全避免 Controller 与 Zk 之间信息不一致导致的各种问题。
Broker 不用再去考虑消息的传递的各种糟糕情况,只使用简单的事件日志来管理元数据及自身状态。当然,这需要确保元数据变更是按顺序到达的。
Broker 可以将这些元数据存储在本地文件中,启动时只需要读取 Controller 中变化的部分,这样 Kafka 就可以用更少的 CPU 消耗启动大量的分区。
元数据可以直接通过 Kafka 获得,而不用再去绕一圈 Zk。另外由于元数据使用了事件日志进行管理,对集群的监控和统计分析也将更加准确且容易实现。
由于 KRaft 模式 存储元数据时使用了和 Offset 相同的顺序读写方式,因此不用再考虑 Zk 随机读写时使用 SSD 对 HDD 的巨大优势。KRaft 模式下只用 HDD 同样可以实现极致的吞吐!
架构对比#
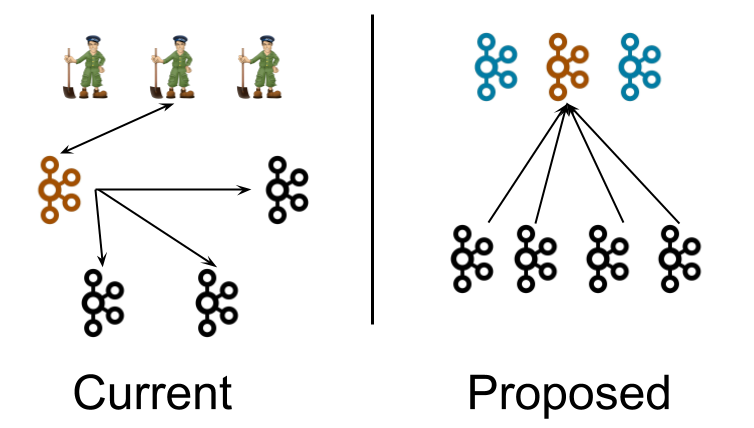
如左图所示,在 Kafka 2.7 及以前,使用 Zk 管理元数据的 Kafka 通过当选的 Controller(橙色节点) 与 Zk 交换元数据。此时 Controller 通过发送 UpdateMetadata 消息 将元数据推送给其他 Broker。
右图展示的为 KRaft 模式 下 Kafka 的架构。三个独立的 Controller 进程替代了原来的 Zk 集群。Broker 节点本地存储一份元数据文件,并且从 Controller 中的 Leader(橙色) 节点拉取元数据的更新(模型类似于消费者从 Broker 消费数据)。